知识点:
一、Prometheus 理论知识
1、Prometheus 介绍?
Prometheus 是一个开源的系统监控和报警系统,现在已经加入到 CNCF 基金会,成为继
k8s 之后第二个在 CNCF 托管的项目,在 kubernetes 容器管理系统中,通常会搭配
prometheus 进行监控,同时也支持多种 exporter 采集数据,还支持 pushgateway 进行数
据上报,Prometheus 性能足够支撑上万台规模的集群。
Prometheus 配置:
Prometheus 监控组件对应的 exporter 部署地址:
Prometheus 基于 k8s 服务发现参考:
2.31/documentation/examples/prometheus-kubernetes.yml
2、Prometheus 特点?
2.1 多维度数据模型:Prometheus 监控系统在收集和存储监控数据时,采用了多维度的时
间序列数据模型,这种模型不仅记录每个监控指标的数据,还会使用标签(labels)为每
个数据点附加额外的信息,使得同一个指标可以有多个维度,便于进行更加细粒度的查询
和分析。
这种结构使得同一个指标可以根据不同的标签维度(如不同的机器、不同的服务、不
同的时间段等)生成不同的时间序列数据。
cpu_usage{instance=”server1″}
avg(cpu_usage) by (instance)
这种多维度的查询使得你不仅能够看到整体的资源使用情况,还可以深入到每个细节,
分析不同维度(如不同节点、不同服务、不同时间等)的表现。
举个例子:
假设你监控了一个 Web 服务,收集了 CPU 和内存的使用情况。通过 Prometheus,你不
仅能看到整体的 CPU 和内存使用情况,还能按每个节点(如 node=”server1″ 和
node=”server2″)或者每个服务(如 service=”frontend”)来查看数据,从而获得更细致
的分析。这种多维度模型,使得监控更加灵活、精准,帮助你快速定位问题和优化资源。
2.2 灵活的数据采集方式:Prometheus 提供了多种方法来采集监控数据,能够适应各种
不同的监控需求,同时确保数据采集的高效性和可靠性。
2.3 强大的查询语言:Prometheus 提供了一种名为 PromQL 的查询语言,它非常强大且
灵活,能够让用户在 Prometheus 中存储的监控数据进行实时查询和复杂的分析操作。官网
->https://prometheus.ac.cn/docs/prometheus/latest/querying/basics/
具体功能如下:
cpu_usage[1h]
avg(cpu_usage) by (instance) [1h]
memory_usage / cpu_usage
http_requests_total{status=”200″} * up
2.4 动态监控和自动发现:Prometheus 支持动态监控和自动发现机制。它可以自动探测和
监控新加入集群的目标,例如新部署的应用实例或新增的节点。通过定义合适的自动发现
规则,Prometheus 能够及时识别和监控新的目标,实现动态的监控配置和管理。
2.5 灵活的告警机制:Prometheus 具备强大的告警功能,用户可以定义灵活的警报规则,
并根据阈值、表达式和持续时间等条件触发警报。它能够及时发送通知,如电子邮件、短
信或调用 API,以便运维人员能够快速响应和解决潜在的问题。
2.6 生态系统和集成:Prometheus 拥有丰富的生态系统和广泛的集成能力。它可以与其他
工具和服务集成,如 Grafana 用于可视化、Alertmanager 用于告警通知、Exporter 用于采
集非 Prometheus 格式的指标数据等。这种集成能力使得用户能够构建全面和强大的监控解
决方案。
2.7 样本
1.时间序列中的每一个点称为一个样本:
在 Prometheus 中,时间序列是一个由多个数据点组成的数据集合,每个数据点代表一个
样本。每个样本包含三部分信息:
• 指标(metric):指明了你监控的对象或事件的名称。例如,你监控的 HTTP 请求
的总数,指标名称可能是 api_http_requests_total。
• 时间戳(timestamp):每个样本都有一个时间戳,标识该数据点记录的具体时间。
时间戳通常精确到毫秒,表示数据采集的时刻。
• 样本值(value):每个样本都有一个值,通常是一个浮动的数值(float64),表示
当前时刻的监控指标值。例如,某个时刻 api_http_requests_total 可能值为 1000,
表示当前时间点 API 请求的总数。
2. 样本的表示方式:
为了表示监控数据,Prometheus 使用特定的格式来展示指标、标签和对应的值。具体格式
为:
<metric name>{<label name>=<label value>, …}
3. 举个例子:
假设你监控的是 API 的 HTTP 请求总数,指标名称为 api_http_requests_total。为了更具体
地标识每个请求,还可以用标签来描述:
• method=”POST”:表示请求方法是 POST。
• handler=”/messages”:表示请求的路径是 /messages。
那么,你的时间序列就可以这样表示:
api_http_requests_total{method=”POST”, handler=”/messages”}
这个表示的是:所有方法为 POST,路径为/messages 的 HTTP 请求的总数。
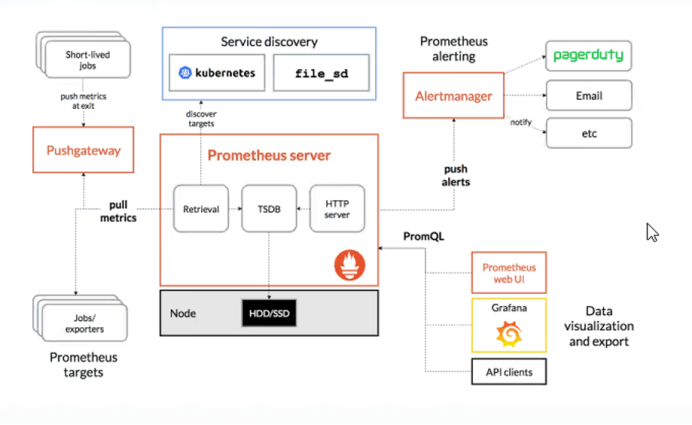
1.Prometheus Server:
• 作用:Prometheus Server 是整个监控系统的核心,负责收集和存储监控数据。
• 比喻:就像一个中央服务器,收集各个设备或应用程序发送的数据。
Prometheus Server 主要由三个部分组成:
1)Retrieval:
• 作用:负责定期从配置的目标主机(比如你的服务器、应用)抓取监控指标数据。
• 比喻:像是“收集员”,它定时去各个目标地方收集数据。
2)Storage:
• 作用:负责把从目标主机抓取到的数据保存到磁盘中,以便后续查询。
• 比喻:它是一个“数据库”,专门存储所有采集到的监控数据。
3)PromQL:
• 作用:PromQL 是 Prometheus 提供的查询语言,用来从存储的数据中提取有用的
信息。
• 比喻:它像 SQL,帮助用户从 Prometheus 存储的数据中进行查询,获取到具体的
监控指标。
2. Client Library:
• 作用:客户端库用于在应用程序代码中嵌入监控功能。当 Prometheus 想要获取监
控数据时,客户端库会把当前应用程序的指标数据(比如 CPU 使用率、内存消耗
等)发送到 Prometheus Server。
• 比喻:类似于每个应用程序内部嵌入的一个“监控代理”,它负责采集应用内部的
数据并传送到 Prometheus。
3. Exporters:
• 作用:Exporters 是一些外部工具或程序,帮助 Prometheus 从不同的系统或应用
中获取监控数据。不同的服务会有不同的 Exporter 适配器,比如数据库、操作系
统、网络设备等。
• 比喻:就像是各种“插件”,它们帮助 Prometheus 从不同地方抓取监控数据。
4. Alertmanager:
• 作用:Alertmanager 是一个报警管理组件。它从 Prometheus Server 收到报警
(比如 CPU 使用率超过阈值)后,会进行去重、分组,并将报警通知发送到相应
的接收方(比如邮箱、微信群、钉钉群等)。
• 比喻:它就像是报警中心,负责接收、整理和转发警报。
5. Grafana:
• 作用:Grafana 是一个可视化工具,用来创建监控仪表盘,帮助用户以图表的形式
展示 Prometheus 收集到的数据。
• 比喻:就像一个“仪表盘”显示器,帮助你通过图形化的方式查看你的数据和监控
情况。
6. Pushgateway:
• 作用:Pushgateway 允许某些无法主动向 Prometheus Server 推送数据的设备
(比如短暂运行的批处理任务)通过 Pushgateway 上报数据,Prometheus Server
再从 Pushgateway 拉取数据。
• 比喻:如果某些任务不能持续运行,Pushgateway 就是它们的临时存储位置,任务
完成后,它们将数据推送到这里,Prometheus 会定期从中拉取。
Prometheus 工作流程
1.Prometheus Server 数据采集
• Prometheus Server 负责从监控目标(通常是运行着应用程序的服务器或者容器)
上定期拉取监控指标数据。默认采用 pull 方式:
o 静态 Job 配置:通过配置文件指定固定的监控目标,Prometheus 将定期从
这些目标上拉取数据。
o 服务发现:通过服务发现(例如 Kubernetes、Consul 等)动态识别并拉取
监控目标的数据。服务发现的好处是能够自动识别目标,而不需要手动指
定。
o Pushgateway:对于一些无法直接提供 HTTP 接口的服务(如批处理作业、
离线任务等),可以将数据推送到 Pushgateway,然后 Prometheus 再拉取
这些数据。
o Exporter:Prometheus 生态系统中有许多专门的 exporter,用于采集特定
系统或应用程序的数据,如 Node Exporter(采集主机的 CPU、内存等资源
数据)和 MySQL Exporter(采集 MySQL 数据库的数据)。这些 exporter 通
过 HTTP 接口提供监控数据,Prometheus 拉取数据时会查询这些接口。
2. 数据存储
• Prometheus 会把采集到的监控数据按时间序列存储,通常存储在本地磁盘中。每
条数据会包含时间戳、度量指标(metric)、**标签(labels)**等信息。
• 数据是时序化存储的,每次拉取到的新数据都会在原有的基础上形成一个新的时间
点,从而形成连续的监控数据流。
3. 时间序列存储与报警规则
• Prometheus 把采集的数据按时间序列存储,每一项数据都会根据其时间戳分配存
储。
• 用户可以在 Prometheus 配置报警规则(alert rules),这些规则基于数据的阈值或
者特定的条件。若条件触发(例如 CPU 使用率超过 80%),Prometheus 会发出报警。
• 这些报警会被 Prometheus 发送给 Alertmanager 进行进一步的处理。
4. Alertmanager 处理报警
• Alertmanager 负责接收 Prometheus 发出的报警信息并处理。它支持多种报警接收
方式,包括:
o 邮件:将报警信息通过邮件发送给相关人员。
o 微信、钉钉:可以集成到企业的即时通讯工具中,实时通知相关人员。
o 其他接收方:Alertmanager 还支持 HTTP 请求、Slack 等其他通知方式。
5. Prometheus Web UI 与 PromQL 查询
• Prometheus 提供一个自带的 Web UI 界面,可以用来查看数据、配置、查询和管理
监控任务。
在 Web UI 中,用户可以使用 PromQL(Prometheus Query Language)进行查询。
PromQL 是专门为 Prometheus 设计的查询语言,可以帮助用户对监控数据进行灵
活的检索和分析,例如求平均值、最大值、最小值,或进行各种聚合操作。
6. Grafana 图形化展示
• Grafana 是一个强大的开源数据可视化工具,可以与 Prometheus 集成作为数据源,
将 Prometheus 采集到的监控数据以图表的形式展示。
• 用户可以在 Grafana 中创建各种仪表盘(Dashboard)并展示实时监控数据。
Grafana 提供了丰富的可视化选项,支持折线图、饼图、柱状图等多种样式,使得
监控数据更加直观易懂。
一、实验环境:
还原到单节点集群:master1\node1\node2,开机
zabbix是监控虚拟机IP;Prometheus是监控pod,进程,pod IP会变。
二、master1上创建监控命名空间monitor-sa;所有节点master1 \node1\node2 都上传node-exporter镜像、并导入运行node-exporter镜像
[root@master1 \node1\node2 ~]# kubectl create ns monitor-sa 创建监控命名空间monitor-sa
namespace/monitor-sa created
[root@master1 \node1\node2~]# ctr -n k8s.io images import node-exporter.tar.gz
unpacking docker.io/prom/node-exporter:v0.965eabe03865ab1595705f4f847009)...done
[root@master1 ~]#三、创建普罗米修斯目录、上传节点的配置文件到prometheus-k8s目录下
[root@master1 ~]# mkdir prometheus-k8s 创建普罗米修斯目录
[root@master1 ~]#
[root@master1 prometheus-k8s]# cd
[root@master1 ~]# ls
anaconda-ks.cfg calico.yaml node_exporter-1.5.0.linux-amd64.tar.gz node-export.yaml
calico.tar.gz kubeadm.yaml node-exporter.tar.gz prometheus-k8s
[root@master1 ~]# cd prometheus-k8s/
[root@master1 prometheus-k8s]# cp /root/node-export.yaml . 上传节点的配置文件到prometheus-k8s目录下
[root@master1 prometheus-k8s]# ls
node-export.yaml
[root@master1 prometheus-k8s]# kubectl apply -f node-export.yaml 应用节点的配置文件
daemonset.apps/node-exporter created四、查看监控命名空间的pod信息、查看监控命名空间的pod详细信息
[root@master1 prometheus-k8s]# kubectl get pods -n monitor-sa 查看监控命名空间的pod信息
NAME READY STATUS RESTARTS AGE
node-exporter-g49bj 1/1 Running 0 22s
node-exporter-hffgm 1/1 Running 0 22s
node-exporter-xflj5 1/1 Running 0 22s
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]# kubectl get pods -n monitor-sa -o wide 查看监控命名空间的pod详细信息
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-g49bj 1/1 Running 0 44s 192.168.7.180 master1 <none> <none>
node-exporter-hffgm 1/1 Running 0 44s 192.168.7.183 node1 <none> <none>
node-exporter-xflj5 1/1 Running 0 44s 192.168.7.184 node2 <none> <none>
[root@master1 prometheus-k8s]#五、查看node节点端口号及字符界面访问node节点的度量值
[root@master1 prometheus-k8s]# netstat -tunlp | grep :9100 查看node节点端口号
tcp6 0 0 :::9100 :::* LISTEN 25942/node_exporter 如果有25942 代表node节点起来了
[root@master1 prometheus-k8s]# curl http://192.168.7.180:9100/metircs 字符界面访问node节点的度量值
<html>
<head><title>Node Exporter</title></head>
<body>
<h1>Node Exporter</h1>
<p><a href="/metrics">Metrics</a></p>
</body>
</html>[root@master1 prometheus-k8s]#
六、在监控空间创建sa(服务)的账号、将监控命名空间的sa账号通过clusterrolebinding绑定到集群角色中
[root@master1 prometheus-k8s]# kubectl create serviceaccount monitor -n monitor-sa 在监控空间创建sa(服务)的账号
serviceaccount/monitor created
[root@master1 prometheus-k8s]# kubectl create clusterrolebinding monitor-clusterrolebindi ng -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
clusterrolebinding.rbac.authorization.k8s.io/monitor-clusterrolebinding created 将监控命名空间的sa账号通过clusterrolebinding绑定到集群角色中
[root@master1 prometheus-k8s]#七、在Node1\node2节点创建数据存储目录/data、将data目录添加777权限
[root@node1 ~]# mkdir /data 在Node1\node2节点创建数据存储目录/data
[root@node1 ~]# chmod 777 /data 将data目录添加777权限
[root@node1 ~]#[root@node2 ~]# mkdir /data
[root@node2 ~]# chmod 777 /data
[root@node2 ~]#八、master1节点上传Prometheus-cfgl普罗米修斯存储卷(主要用来存放配置文件)的配置文件
[root@master1 /]# cd
[root@master1 ~]# cd prometheus-k8s/
[root@master1 prometheus-k8s]# cp /root/prometheus-cfg.yaml .
[root@master1 prometheus-k8s]# ls
node-export.yaml prometheus-cfg.yaml
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]# kubectl apply -f prometheus-cfg.yaml 应用普罗米修斯存储卷的配置文件(主要用来存放配置文件)
configmap/prometheus-config created
[root@master1 prometheus-k8s]# kubectl get cm -n monitor-sa 查看监控命名空间,用来获取监控命名空间下的ConfigMap资源
NAME DATA AGE
kube-root-ca.crt 1 53m
prometheus-config 1 20s
[root@master1 prometheus-k8s]#九、Node1\node2上传prometheus-2.2.1.tar(普罗米修斯的镜像文件)、并运行prometheus-2.2.1.tar的镜像文件

[root@node1 ~]# ls
anaconda-ks.cfg calico.tar.gz prometheus-2-2-1.tar.gz
busybox-1-28.tar.gz node-exporter.tar.gz prometheus-cfg.yaml
[root@node1 ~]# ctr -n k8s.io images import prometheus-2-2-1.tar.gz node1\node2节点导入普罗米修斯的镜像文件
unpacking docker.io/prom/prometheus:v2.2.1 (sha256:9b21b0369c9816ebd0bb41237def3de7e28c36cdc7a3e35e877c6475ef982d4a)...done
[root@node1 ~]#
[root@node1 ~]#[root@node2 ~]# ctr -n k8s.io images import prometheus-2-2-1.tar.gz
unpacking docker.io/prom/prometheus:v2.2.1 (sha256:9b21b0369c9816ebd0bb41237def3de7e28c36cdc7a3e35e877c6475ef982d4a)...done
[root@node2 ~]#十、将Prometheus的配置部署文件放到prometheus-k8s目录下

[root@master1 ~]# ls
anaconda-ks.cfg node_exporter-1.5.0.linux-amd64.tar.gz prometheus-deploy.yaml
calico.tar.gz node-exporter.tar.gz prometheus-k8s
calico.yaml node-export.yaml
kubeadm.yaml prometheus-cfg.yaml
[root@master1 ~]# cd prometheus-k8s/
[root@master1 prometheus-k8s]# cp /root/prometheus-deploy.yaml . 将Prometheus的配置部署文件放到prometheus-k8s目录下
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]# vim prometheus-deploy.yaml 编辑普罗米修斯无状态的配置文件
25 spec:
26 nodeName: node1 添加node1\node2节点信息(有多少节点添加多少个节点名称,需注意对齐)
27 nodeName: node2[root@master1 prometheus-k8s]# kubectl apply -f prometheus-deploy.yaml 应用普罗米修斯无状态的配置文件
deployment.apps/prometheus-server created
[root@master1 prometheus-k8s]# kubectl get pods -n monitor-sa 查看监控命名空间的pod信息
NAME READY STATUS RESTARTS AGE
node-exporter-g49bj 1/1 Running 0 56m
node-exporter-hffgm 1/1 Running 0 56m
node-exporter-xflj5 1/1 Running 0 56m
prometheus-server-6fc5b6f457-sp48r 看这个 1/1 Running 0 16s
[root@master1 prometheus-k8s]#十一、创建prometheus-svc普罗米修斯服务的配置文件
[root@master1 prometheus-k8s]# vim prometheus-svc.yaml 创建普罗米修斯服务的配置文件
apiVersion: v1 api版本为1
kind: Service 类型:服务
metadata: 元数据
name: prometheus 名称为:普罗米修斯
namespace: monitor-sa 命名空间:监控monitor-sa
labels: 卷标的名称为:普罗米修斯
app: prometheus
spec:
type: NodePort 类型为:nodeport
ports:
- port: 9090 源端口:9090
targetPort: 9090 目标端口:9090
protocol: TCP 协议:tcp协议
selector: 调度器
app: prometheus 使用:普罗米修斯
component: server 组成部分为:服务器
~
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]# kubectl apply -f prometheus-svc.yaml
service/prometheus created
[root@master1 prometheus-k8s]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.110.208.180 <none> 9090:31087/TCP 15s
[root@master1 prometheus-k8s]#[root@master1 prometheus-k8s]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-7dc5458bc6-5jztl 1/1 Running 2 (89m ago) 11d 10.244.137.72 master1 <none> <none>
calico-node-clzfg 1/1 Running 2 (89m ago) 11d 192.168.7.183 node1 <none> <none>
calico-node-kbqjt 1/1 Running 2 (89m ago) 11d 192.168.7.180 master1 <none> <none>
calico-node-ng6b2 1/1 Running 2 (89m ago) 11d 192.168.7.184 node2 <none> <none>
coredns-7c445c467-kff9r 1/1 Running 2 (89m ago) 11d 10.244.137.71 master1 <none> <none>
coredns-7c445c467-mmcg7 1/1 Running 2 (89m ago) 11d 10.244.137.73 master1 <none> <none>
etcd-master1 1/1 Running 2 (89m ago) 11d 192.168.7.180 master1 <none> <none>
kube-apiserver-master1 1/1 Running 2 (89m ago) 11d 192.168.7.180 master1 <none> <none>
kube-controller-manager-master1 1/1 Running 2 (89m ago) 11d 192.168.7.180 master1 <none> <none>
kube-proxy-6kdb8 1/1 Running 2 (89m ago) 11d 192.168.7.180 master1 <none> <none>
kube-proxy-gq9js 1/1 Running 2 (89m ago) 11d 192.168.7.184 node2 <none> <none>
kube-proxy-vjm2p 1/1 Running 2 (89m ago) 11d 192.168.7.183 node1 <none> <none>
kube-scheduler-master1 1/1 Running 2 (89m ago) 11d 192.168.7.180 master1 <none> <none>
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]#十二、浏览器上访问配置好的Prometheus监控k8s的服务器
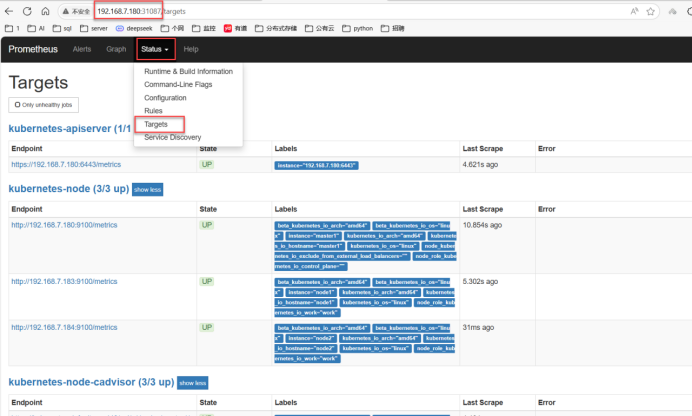
十三、node1\node2上传grafana8.45.tar,运行此镜像

[root@node1 ~]# ls
anaconda-ks.cfg calico.tar.gz node-exporter.tar.gz prometheus-cfg.yaml
busybox-1-28.tar.gz grafana_8.4.5.tar.gz prometheus-2-2-1.tar.gz
[root@node1 ~]# ctr -n k8s.io images import grafana_8.4.5.tar.gz node1\node2导入grafana的镜像文件
unpacking docker.io/grafana/grafana:8.4.5 (sha256:b862eb2a74c35f1dedea901ec93f8303f8ea6f1125b5005ff719912ae31267b8)...done
[root@node1 ~]#[root@node2 ~]# ctr -n k8s.io images import grafana_8.4.5.tar.gz
unpacking docker.io/grafana/grafana:8.4.5 (sha256:b862eb2a74c35f1dedea901ec93f8303f8ea6f1125b5005ff719912ae31267b8)...done
[root@node2 ~]#十四、master1节点上上传grafana配置文件及编辑此配置文件:

[root@master1 prometheus-k8s]# vim grafana.yaml 编辑grafana配置文件
17 spec:
18 nodeName: node1 添加节点名称为node1和node2
19 nodeName: node2
[root@master1 prometheus-k8s]#apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
nodeName: xianchaonode1
containers:
- name: grafana
image: grafana/grafana:8.4.5
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
- mountPath: /var/lib/grafana/
name: lib
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
- name: lib
hostPath:
path: /var/lib/grafana/
type: DirectoryOrCreate
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort十五、node1\node2创建grafana目录并添加777权限:
[root@node1 ~]# mkdir -p /var/lib/grafana 在node1、node2节点创建grafana的目录
[root@node1 ~]#
[root@node1 ~]# chmod 777 /var/lib/grafana 给grafana添加777权限
[root@node1 ~]#[root@node2 ~]# mkdir -p /var/lib/grafana
[root@node2 ~]#
[root@node2 ~]#
[root@node2 ~]# chmod 777 /var/lib/grafana
[root@node2 ~]#十六、master1应用grafana的配置文件并查看grafana监控 的状态:
[root@master1 prometheus-k8s]# kubectl apply -f grafana.yaml 应用grafana的配置文件
deployment.apps/monitoring-grafana created
service/monitoring-grafana created
[root@master1 prometheus-k8s]# kubectl get pods -n kube-system | grep monitor 查看grafana的pod信息
monitoring-grafana-5b6798596c-lw25h 1/1 Running 0 22s
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]# kubectl get svc -n kube-system | grep grafana
monitoring-grafana NodePort 10.107.63.241 <none> 80:32424/TCP 4m37s
[root@master1 prometheus-k8s]#十七、查看grafana的监控平台:
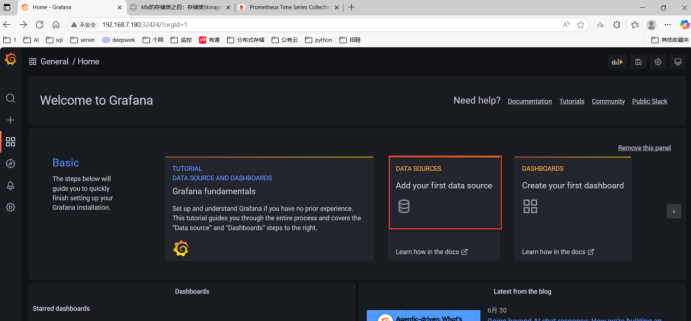
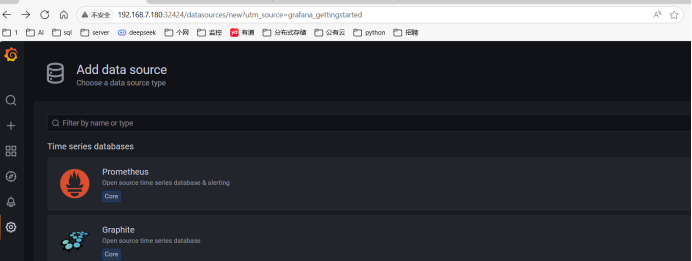

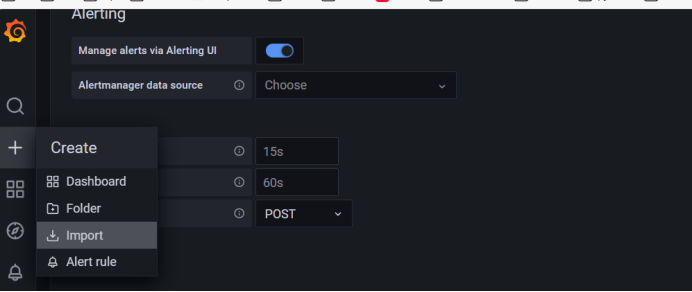
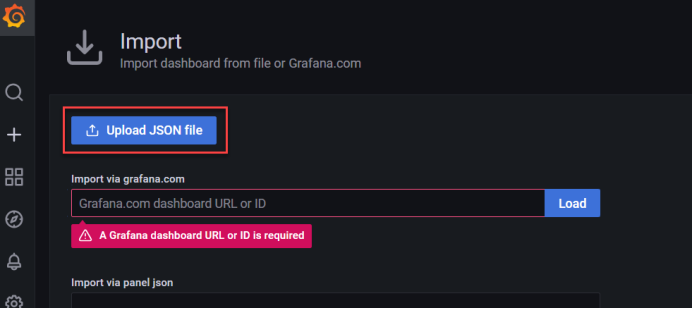

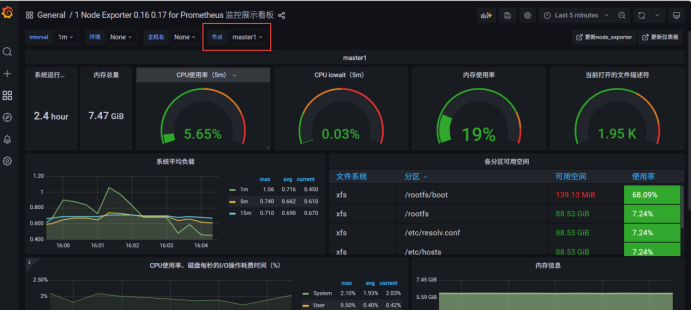
十八、安装kube-state-metrics组件
kube-state-metrics 是什么?
kube-state-metrics 通过监听 API Server 生成有关资源对象的状态指标,比如 Node、
Pod,需要注意的是 kube-state-metrics 只是简单的提供一个 metrics 数据,并不会
存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储,主要关
注的是业务相关的一些元数据,比如 Pod 副本状态等;调度了多少个 replicas?现在
可用的有几个?多少个 Pod 是 running/stopped/terminated 状态?Pod 重启了多少次?
我有多少 job 在运行中。
十九、node1\node2节点上上传kube-state-metrics_1_9_0.tar镜像并运行此镜像
[root@node1 ~]# ctr -n k8s.io images import kube-state-metrics_1_9_0.tar.gz node1导入kube-state-metrics的镜像
unpacking quay.io/coreos/kube-state-metrics:v1.9.0 (sha256:bf40aa1452dcefe34680c595995af1f4a72b7a480b3597fe863a3a5c4e8dde42)...done
[root@node1 ~]#[root@node2 ~]# ctr -n k8s.io images import kube-state-metrics_1_9_0.tar.gz node2导入kube-state-metrics的镜像
unpacking quay.io/coreos/kube-state-metrics:v1.9.0 (sha256:bf40aa1452dcefe34680c595995af1f4a72b7a480b3597fe863a3a5c4e8dde42)...done
[root@node2 ~]#二十、master1 prometheus-k8s上传kube-state-metrics-rbac、prometheus-deploy配置文件

[root@master1 prometheus-k8s]# ls
grafana.yaml node-export.yaml prometheus-deploy.yaml
kube-state-metrics-rbac.yaml prometheus-cfg.yaml prometheus-svc.yaml
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]# kubectl apply -f kube-state-metrics-rbac.yaml #应用kube-state-metrics-rbac配置文件
#kube-state-metrics-rbac 配置文件的目的:创建sa,并对sa进行授权
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created应用kube-state-metrics无状态的配置文件
[root@master1 prometheus-k8s]# kubectl apply -f kube-state-metrics-deploy.yaml
deployment.apps/kube-state-metrics created
[root@master1 prometheus-k8s]#[root@master1 prometheus-k8s]# ls
grafana.yaml kube-state-metrics-deploy.yaml 看这个 kube-state-metrics-rbac.yaml node-export.yaml prometheus-cfg.yaml prometheus-deploy.yaml prometheus-svc.yaml
[root@master1 prometheus-k8s]# 二十一、查看kube-state-metrics的状态
[root@master1 prometheus-k8s]# kubectl get pods -n kube-system -l app=kube-state-metrics 查看kube-state-metrics pod信息 NAME READY STATUS RESTARTS AGE
kube-state-metrics-66b85747b7-f6c95 1/1 Running 0 2m22s
[root@master1 prometheus-k8s]#二十二、master1 prometheus-k8s上传kube-state-metrics-svc配置文件
[root@master1 prometheus-k8s]# kubectl apply -f kube-state-metrics-svc.yaml 应用kube-state-metrics服务的配置文件
service/kube-state-metrics created
[root@master1 prometheus-k8s]#[root@master1 prometheus-k8s]# kubectl get svc -n kube-system -l app=kube-state-met 查看kube-state-metrics的服务 rics 查看kube-state-metrics的pod
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-state-metrics ClusterIP 10.110.158.228 <none> 8080/TCP 74s
[root@master1 prometheus-k8s]#
[root@master1 prometheus-k8s]#二十三、grafana上上传k8s集群的配置文件

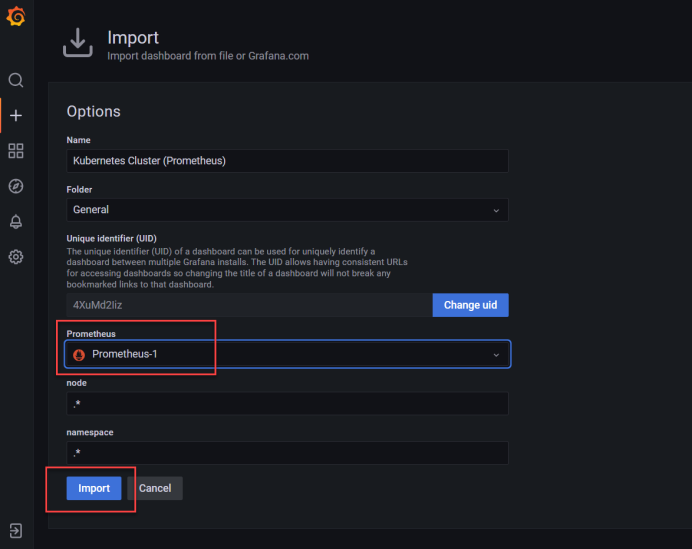
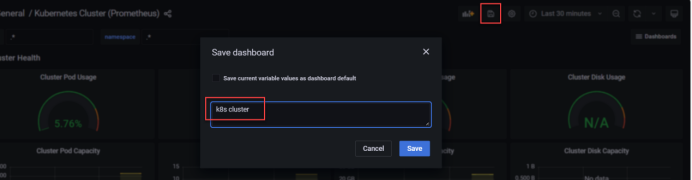
二十四、grafana上传集群监控的配置文件

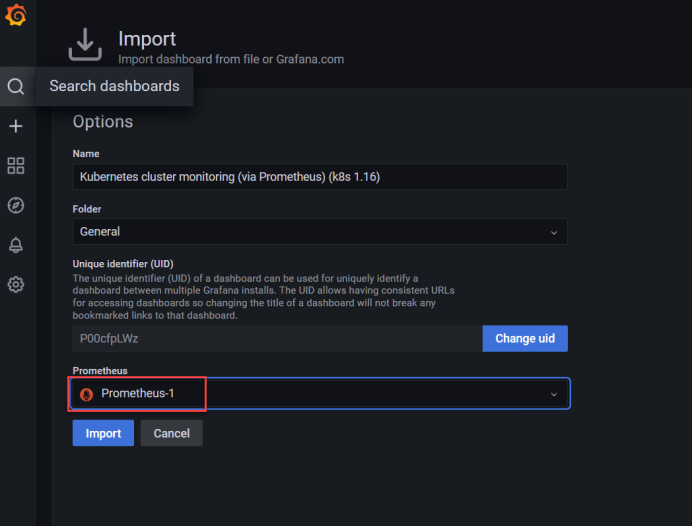
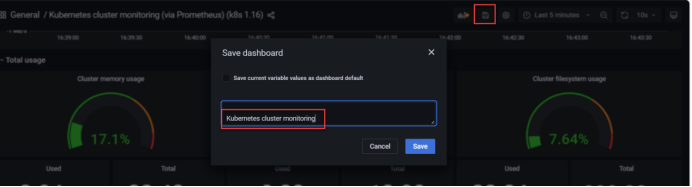
十二五、master1、node1、node2关机做快照,快照名称:
Prometheus和grafana配置完成